一种Python中模拟多线程计算的方案
问题场景
Python并发编程绕不开全局锁(GIL)的问题。简单来说,GIL保证了一段时间内只允许一个真实的thread运行。网上有大量关于这个问题的历史成因的解释及性能瓶颈的测试结果。总结来说,当程序为IO密集型的时候,多线程其实也还是个不错的方案,但如果是运算密集型的情况下,CPU的资源就不能很好的分配和利用了。
在最近实验室的项目中,需要开发一个针对Entity Resolution问题的包,我们叫它Record Linkage ToolKit (RLTK)。在使用RLTK的时候,我们希望可以使用多线程来加速运算,但很多依赖包或者是用户代码都是线程不安全的;于此同时,RLTK的使用场景不允许进行输入文件的预先切割然后并行的跑几个不同的并行进程。
针对这些问题,我在RLTK的实现中给出了一个通用的方案。
实现方案
最直观的代替多线程的方案就是多进程(这也是官方推荐的),但是多进程的优缺点也很明显:优点当然是内存的独立互不影响同时能很好的使用CPU的多核,这也是为何Chrome需要一个tab一个进程;缺点也是内存空间的独立(好一把双刃剑),进程间数据交换过程繁琐,于是就诞生了各种IPC技术。
RLTK的使用场景归纳后其实就是:开始->单线程->并发/并行->单线程->并发/并行->...->单线程->结束。注意此处我没有区别并发(Concurrent)和并行(Parallel)这两个完全不同的概念,是因为此处我的目的无非就是通过某种手段实现CPU资源的最大化利用。
在这个场景中,“并发/并行”可以看成一组并行的运算作业 (RLTK中主要是算Feature Vector),运算期间各个单元是独立的(即在运算过程中不需要数据交互),如果每个作业单元的输入为input[i]输出单元为output[i],则问题模型可以抽象成output[i]=F(input[i]),其中的并行部分无非就是一个黑盒函数F。因此无非就是在必要的时候把数据切割成多份然后丢入进程池去并行运行。
这之后还需要解决的问题就是输出的返回。最简单的方案当然就是直接输出到不同的文件中,之后程序主线程等待运算结束后统一读取并合并结果,但这样的坏处是额外的磁盘IO的开销。因此方案变成,主进程中再创建一条副线程专门用于output的合并,主线程需要等所有子进程和副线程退出后才能继续执行下去。数据的输入和输出通过Queue进行交换。时间线如下:
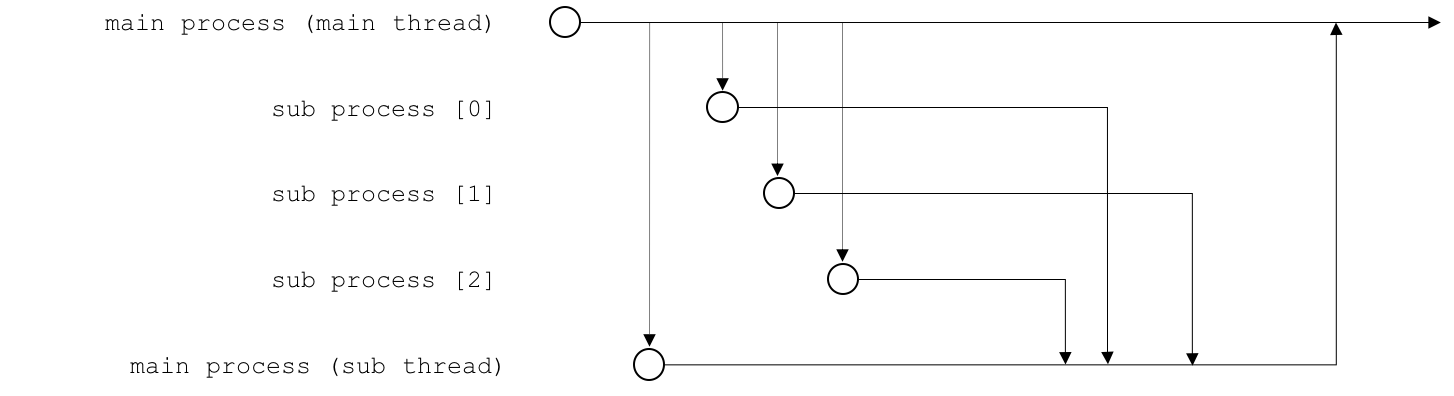
注意主进程中两个线程将由CPU调配交替运行,子进程中均只有各自的主线程因此无线程切换。这个设计在使用的时候需要将运算尽可能的在子进程中完成,主进程的子线程仅仅负责运算结果的获取和合并。
具体代码实现 (github):
"""
This module is designed for breaking the restriction of Python Global Interpreter Lock (GIL): It uses multi-processing (compute-intensive operations) and multi-threading (return data collecting) to accelerate computing.
Once it's initialized, it creates a sub process pool, all the added data will be dispatched to different sub processes for parallel computing. The result sends back and consumes in another thread in current main process. The Inter Process Communication (IPC) between main process and sub processes is based on queue.
Example::
result = []
def dummy_computation_with_input(x):
time.sleep(0.0001)
return x * x, x + 5
def output_handler(r1, r2):
result.append(r1 if r1 > r2 else r2)
pp = ParallelProcessor(dummy_computation_with_input, 8, output_handler=output_handler)
pp.start()
for i in range(8):
pp.compute(i)
pp.task_done()
pp.join()
print(result)
"""
import multiprocessing as mp
import threading
import queue
from typing import Callable
class OutputThread(threading.Thread):
"""
Handle output in main process.
Create a thread and call ParallelProcessor.get_output().
"""
def __init__(self, instance, output_handler):
super(OutputThread, self).__init__()
self.output_handler = output_handler
self.instance = instance
def run(self):
for o in self.instance.get_output():
self.output_handler(*o)
class ParallelProcessor(object):
"""
Args:
input_handler (Callable): Computational function.
num_of_processor (int): Number of processes to use.
max_size_per_input_queue (int): Maximum size of input queue for one process.
If it's full, the corresponding process will be blocked.
0 by default means unlimited.
max_size_per_output_queue (int): Maximum size of output queue for one process.
If it's full, the corresponding process will be blocked.
0 by default means unlimited.
output_handler (Callable): If the output data needs to be get in main process (another thread),
set this handler, the arguments are same to the return from input_handler.
The return result is one by one, order is arbitrary.
Note:
Do NOT implement heavy compute-intensive operations in output_handler, they should be in input_handler.
"""
# Command format in queue. Represent in tuple.
# The first element of tuple will be command, the rests are arguments or data.
# (CMD_XXX, args...)
CMD_DATA = 0
CMD_STOP = 1
def __init__(self, input_handler: Callable, num_of_processor: int,
max_size_per_input_queue: int = 0, max_size_per_output_queue: int = 0,
output_handler: Callable = None):
self.num_of_processor = num_of_processor
self.input_queues = [mp.Queue(maxsize=max_size_per_input_queue) for _ in range(num_of_processor)]
self.output_queues = [mp.Queue(maxsize=max_size_per_output_queue) for _ in range(num_of_processor)]
self.processes = [mp.Process(target=self.run, args=(i, self.input_queues[i], self.output_queues[i]))
for i in range(num_of_processor)]
self.input_handler = input_handler
self.output_handler = output_handler
self.input_queue_index = 0
self.output_queue_index = 0
# output can be handled in each process or in main process after merging (output_handler needs to be set)
# if output_handler is set, output needs to be handled in main process; otherwise, it assumes there's no output.
if output_handler:
self.output_thread = OutputThread(self, output_handler)
def start(self):
"""
Start processes and threads.
"""
if self.output_handler:
self.output_thread.start()
for p in self.processes:
p.start()
def join(self):
"""
Block until processes and threads return.
"""
for p in self.processes:
p.join()
if self.output_handler:
self.output_thread.join()
def task_done(self):
"""
Indicate that all resources which need to compute are added to processes.
(main process, blocked)
"""
for q in self.input_queues:
q.put((ParallelProcessor.CMD_STOP,))
def compute(self, *args, **kwargs):
"""
Add data to one of the input queues.
(main process, unblocked, using round robin to find next available queue)
"""
while True:
q = self.input_queues[self.input_queue_index]
self.input_queue_index = (self.input_queue_index + 1) % self.num_of_processor
try:
q.put_nowait((ParallelProcessor.CMD_DATA, args, kwargs))
return # put in
except queue.Full:
continue # find next available
def run(self, idx: int, input_queue: mp.Queue, output_queue: mp.Queue):
"""
Process’s activity. It handles queue IO and invokes user's input handler.
(subprocess, blocked, only two queues can be used to communicate with main process)
"""
while True:
data = input_queue.get()
if data[0] == ParallelProcessor.CMD_STOP:
# print(idx, 'stop')
if self.output_handler:
output_queue.put((ParallelProcessor.CMD_STOP,))
return
elif data[0] == ParallelProcessor.CMD_DATA:
args, kwargs = data[1], data[2]
# print(idx, 'data')
result = self.input_handler(*args, **kwargs)
if not isinstance(result, tuple): # output must represent as tuple
result = (result,)
if self.output_handler:
output_queue.put((ParallelProcessor.CMD_DATA, result))
def get_output(self):
"""
Get data from output queue sequentially.
(main process, unblocked, using round robin to find next available queue)
"""
if not self.output_handler:
return
while True:
# print(self.output_queues)
q = self.output_queues[self.output_queue_index]
try:
data = q.get_nowait() # get out
if data[0] == ParallelProcessor.CMD_STOP:
del self.output_queues[self.output_queue_index] # remove queue if it's finished
elif data[0] == ParallelProcessor.CMD_DATA:
yield data[1]
except queue.Empty:
continue # find next available
finally:
if len(self.output_queues) == 0: # all finished
return
self.output_queue_index = (self.output_queue_index + 1) % len(self.output_queues)
设计中input queue和output queue均限制了大小并在填满后阻塞,直到各自的消费者(分别是子进程、主进程的子线程)消费掉相应产品后才会继续执行,保证了内存不会被撑爆。比如:主进程的子线程无法快速消费运算结果->阻塞子进程output queue->阻塞主进程主线程输入input queue。
实现本身采用了相对底层的模块完成,没有使用multiprocessing自带的进程池和JoinableQueue是为了保留更多的自定义扩展可能性。
可能的改进
作为一个通用方案,很显然它的通用型和性能还可以进一步提升。我目前能想到的:
- 可能可以使用协程(Coroutine)代替线程,但是这个方案如何实现有待斟酌:1.我并不清楚Python的多进程Queue是否能当作aio中的Queue使用 2.何时切换生产者和消费者的执行
- 可以引入
multiproecssing.Manager中基础数据类型,从而实现黑盒函数执行期间的跨进程变量修改